引言
上个月,一位做法律咨询创业的朋友找到我,说他花了三万块钱买显卡、熬夜看教程折腾了两周,结果AI模型微调出来的模型不仅没变聪明,反而连原本的基础能力都丢了——问它“今天天气怎么样”,它开始一本正经地背诵民法典条款。
这不是个例。我见过太多人拿着开源模型就开跑,数据随便整理一下,参数照着别人的博客抄,最后在AI模型微调的道路上收获一个“精神分裂”的模型。
微调这件事,说难不难,说简单也绝不简单。它不像训练大模型那样需要核聚变级别的算力,但也没有“一键变强”的魔法。真正的难点在于:流程长、坑点多、每一步出错都可能前功尽弃。
今天这篇指南,我把过去两年实操过的十几个AI模型微调项目经验,浓缩成7个核心步骤和5个避坑要点。从数据清洗到Loss曲线解读,从LoRA参数设置到生产环境部署,帮你把这条路走通、走顺。
前置准备
开始之前,请确保你手头有以下三样东西:
第一,一台有显卡的机器。 不必是A100/H100这种奢侈品。一张RTX 3090/4090(24GB显存)足以应付7B-13B模型的LoRA微调。如果没有,云GPU是个好选择,按小时租用成本可控。
第二,一个想微调的基座模型。 推荐从HuggingFace上下载,中文场景首选Qwen系列(通义千问)、Yi系列或LLaMA的中文版。选模型有个原则:不是越大越好。7B模型跑得快、好调试,13B效果更好但成本翻倍,34B以上建议先等等。
第三,明确你的目标。 你是想让模型学会特定格式(比如总是用JSON输出)?还是想灌输新知识(比如你们公司的内部文档)?或是想改变语气风格(更幽默/更正式)?不同的目标对应不同的数据准备策略,这是后面所有工作的前提。
核心步骤
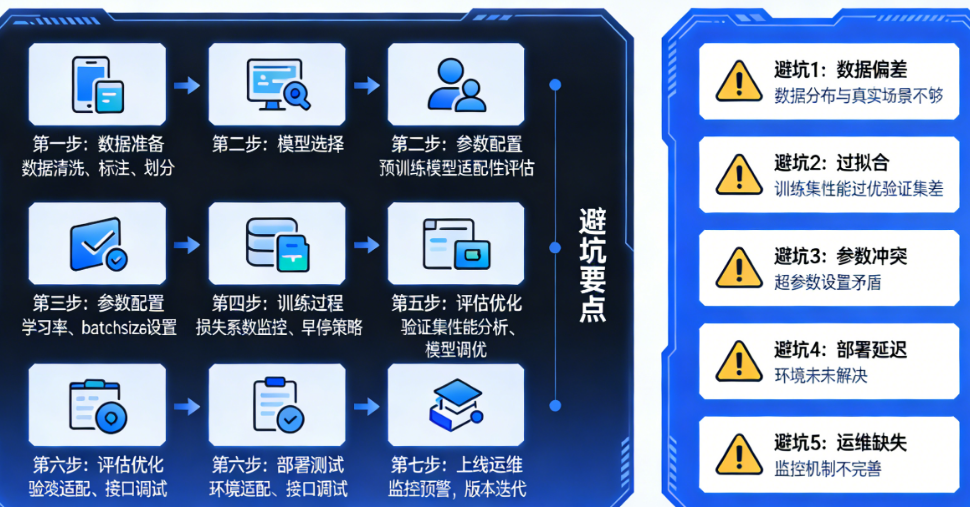
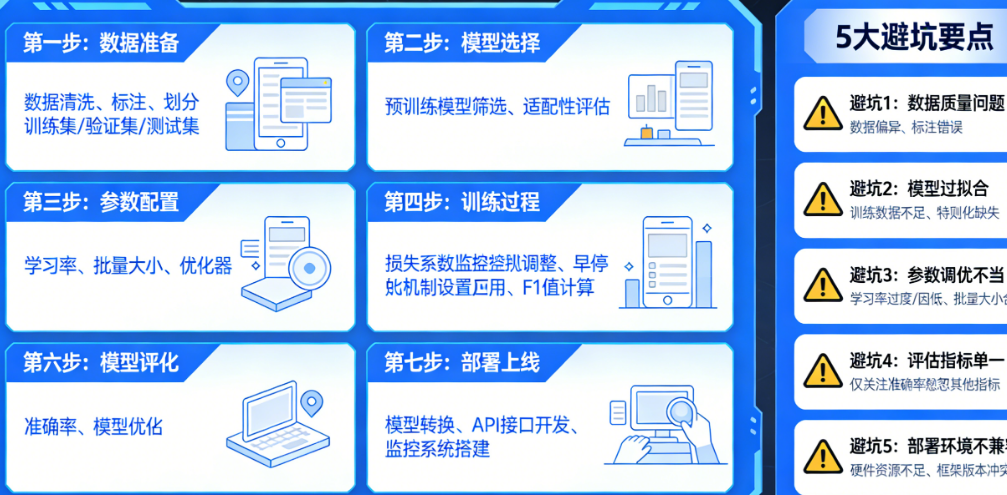
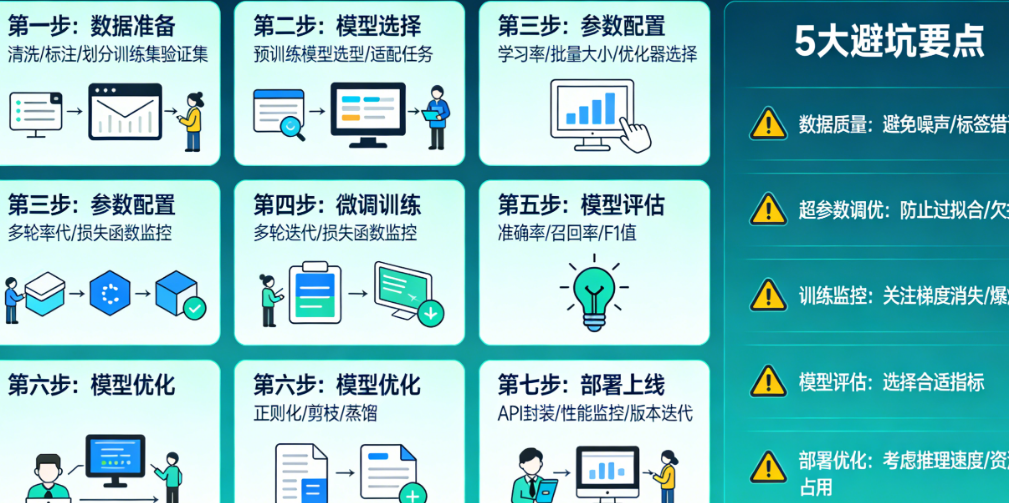
步骤一:数据采集与清洗——垃圾进,垃圾出
这是最重要的一步,也是新手最容易轻视的一步。
先说数据量:质量远大于数量。5000条高质量的“问题-答案”对,效果往往好过5万条从网上随便扒的脏数据。
数据从哪里来?三个渠道:
公开数据集:HuggingFace上有大量指令微调数据集(Alpaca、OpenOrca、COIG等)。优点是免费,缺点是不够垂直
业务日志:如果你有线上产品的用户对话日志,这是金矿。需要脱敏处理。
合成数据:用GPT-4或Claude生成一批数据,人工校对。成本最低,质量可控。
数据清洗阶段必须做三件事:
去重:同样的问答出现多次,会让模型过拟合
格式统一:所有数据统一成{“instruction”: “…”, “input”: “…”, “output”: “…”}格式
质量抽查:随机抽100条人工看一遍,剔除答非所问、逻辑混乱的坏样本
一个血的教训:我见过有人直接拿知乎问答爬虫喂进去,结果模型学会了知乎体——“谢邀,刚下飞机”,但对业务问题一问三不知。
步骤二:数据格式化与拆分——给模型准备标准餐
不同模型要求的输入格式不同,这一步必须对齐。
以Qwen为例,它的标准指令格式是:
text
system
你是一个有用的助手
user
你是谁?
assistant
我是一个AI助手
你需要把自己的问答数据转换成这种格式。写个Python脚本批量处理,注意system prompt(系统提示词)可以根据场景自定义,比如“你是一个专业的法律顾问”。
处理完后,按8:1:1的比例拆分成训练集、验证集、测试集。验证集用来监控训练过程是否过拟合,测试集用来最终评估效果。
步骤三:选择微调方法——LoRA还是全参数?
这是技术选型的关键节点,直接决定你的算力成本和最终效果。
LoRA(低秩适配):当前事实上的标准。它冻结原模型参数,只训练一小部分新增参数(通常占总参数量0.1%-1%)。优点是显存占用低(7B模型用LoRA只需要16GB左右显存)、训练快、不易过拟合。缺点是上限略低于全参数微调。
全参数微调:所有参数都更新。效果上限更高,但需要更大显存(7B模型至少需要60GB以上)、更长训练时间、更容易灾难性遗忘(模型忘了原本学过的知识)。
给新手的建议:90%的场景用LoRA就够了。 先从LoRA开始,跑通流程后再考虑是否需要全参数。
步骤四:配置训练参数——抄作业也要懂原理
这一步最容易让人头大。一堆参数——learning rate、batch size、epochs——到底怎么设?
给你一组经过验证的“起手式”:
text
LoRA参数:
- r(秩): 8 或 16(数据量大用16)
- lora_alpha: 16 或 32(通常设为r的两倍)
- target_modules: q_proj, v_proj(对LLaMA系)或全部线性层(对Qwen)
训练参数:
- learning rate: 2e-4 到 5e-4(LoRA专用,比全参数高)
- batch size: 根据显存能塞下多少算多少,一般4-8
- epochs: 3 到 5(数据少用小,数据多用大)
- warmup steps: 训练总步数的10%
记住一个原则:先从保守参数开始。lr=2e-4,epochs=3,跑一轮看看Loss曲线,再决定要不要调整。
步骤五:启动训练——盯着Loss曲线看什么?
一切准备就绪,敲下训练命令。
这时候不是干等着刷手机。你要盯着Loss曲线(损失函数曲线)看三个东西:
训练Loss是否平稳下降:如果剧烈震荡,说明学习率太高,需要调低
验证Loss是否同步下降:如果训练Loss下降但验证Loss不降或上升,说明过拟合,需要增加数据量或降低epochs
最终Loss值:没有绝对标准,但通常降到1.0以下算不错,0.5以下很优秀
用wandb(Weights & Biases)或TensorBoard实时监控,比黑盒跑完再看结果,能帮你省下大量试错时间。
步骤六:评估与迭代——别只看loss,要看对话
很多人犯的错误:训练完了看一眼Loss=0.3,就觉得大功告成。
Loss低不等于效果好。唯一的检验标准是:用测试集里的问题,一条条问它,看回答质量。
建一个评估集,包含三类问题:
训练集里见过的(检查是否记住了)
同分布但没见过的(检查泛化能力)
分布外的常识问题(检查是否灾难性遗忘)
用这三个维度打分。如果发现模型在某些问题上变笨了,可能是LoRA的target_modules设置不合理,或者数据覆盖不全。调整后再跑一轮——微调本身就是一个迭代过程。
步骤七:导出与部署——让模型真正工作
最后一步,把训练好的模型推到生产环境。
如果是LoRA微调,你得到的是两个东西:基座模型(不变)和LoRA权重(很小,通常几十MB)。部署时需要合并权重,或者用支持LoRA的推理框架。
部署选项有三档:
本地运行:用户自备显卡,你提供模型文件。成本最低,适合开源项目。
API服务:用vLLM、TGI(Text Generation Inference)等框架封装成API。7B模型单卡能扛中等并发,月成本约2000-5000元。
SaaS平台:直接部署到魔搭、HuggingFace等平台,它们提供推理API,按调用量收费。
建议:MVP阶段用2或3,跑通业务后再考虑优化成本。
常见问题与避坑指南
Q1:微调后模型变笨了,连简单问题都不会,怎么办?
A:这是典型的灾难性遗忘。原因可能是数据太单一(全是法律问答,忘了日常对话),或者学习率太高。解决方案:1)在数据里混入20%-30%的通用对话数据;2)降低学习率;3)用LoRA而不是全参数微调。
Q2:Loss一直在降,但生成的内容乱码/重复,怎么回事?
A:大概率是过拟合。模型把训练数据背下来了,但没学会泛化。解决方案:减少epochs,增加dropout,检查数据是否过于单一。
Q3:显存不够怎么办?
A:四个方案:1)用LoRA或QLoRA(4-bit量化版LoRA);2)减小batch size;3)用梯度累积(gradient accumulation);4)换小模型(7B换成3B)。
Q4:微调需要多少数据才够?
A:没有一个绝对数字,但经验值是:想让模型学会新格式/新风格,几百条就够;想让模型学会新知识,需要几千条;想让模型学会复杂推理,可能需要上万条。从500条开始试,效果不够再加。
Q5:微调一次要多久?
A:7B模型+5000条数据+LoRA+RTX 4090,约1-2小时。13B模型+1万条数据+LoRA,约4-6小时。全参数微调时间乘以5-10倍。
进阶技巧
如果你已经跑通基础流程,想让模型效果更上一层楼,这三个技巧能帮到你:
技巧一:数据增强
把现有数据做同义改写、反问、多轮对话扩展。一条数据变三条,数据量瞬间翻倍。可以用GPT-4帮你做改写,成本低效果好。
技巧二:多任务微调
别只做单一任务。在法律问答数据里混入一些通用对话、摘要生成、翻译数据,让模型保持多样性,能有效缓解灾难性遗忘。
技巧三:DPO偏好优化
如果你有“好回答”和“坏回答”的对比数据,可以在SFT(监督微调)之后再做一步DPO(直接偏好优化),让模型更符合人类偏好。这是目前让模型“更懂你”的最前沿技术。
总结
从数据准备到部署上线,AI模型微调的7个核心步骤环环相扣。数据是地基,清洗不到位后面全是白费;参数是工具,理解原理才能调好;评估是标尺,不看对话只看Loss就是自欺欺人。
5大避坑要点其实归结为一句话:别急。别急着跑全参数,别急着上大模型,别急着跳步骤。用小成本跑通闭环,再用放大镜优化细节——这才是微调的正确姿势。
如果你在实操中遇到没覆盖到的问题,欢迎在评论区留言,我们会持续更新这篇指南。
途傲科技:让专业的人做专业的事
如果你正在寻找靠谱的AI算法人才,或者希望将自己的模型微调能力变现,途傲科技网是你的不二选择。作为国内领先的创意服务众包平台,途傲科技汇聚了超过百万的专业服务商,提供涵盖大模型微调、数据标注、GPU算力租赁、模型部署等全品类的技术服务。

任务大厅:发布需求,坐等应征
无论你需要微调一个法律咨询大模型,还是需要批量标注行业数据,只需在任务大厅发布详细需求,百万服务商将主动接单。你可以在线比稿、比较案例、沟通细节,找到最适合项目的合作伙伴。
人才大厅:主动搜索,精准对接
如果你想直接寻找AI领域的大牛,人才大厅提供了强大的筛选功能。你可以按技术栈(PyTorch/TensorFlow)、项目经验(大模型微调、LoRA)、报价等维度筛选,一键雇佣。
服务大厅与商铺案例参考
每个服务商都有自己的服务大厅和商铺,展示历史案例、客户评价和服务特长。在正式合作前,花几分钟浏览他们的商铺,看看过往的AI项目案例,能帮你做出更明智的决定。
威客攻略与V客优享
想了解如何评估微调效果?想知道数据标注的行业报价标准?威客攻略栏目汇集了千万威客的实战经验。加入V客优享,还能享受专属任务推送、交易保障、工作坊培训等增值服务,真正“改变你的工作方式”。
一品商城:标准化产品,快速交付
对于需求明确、预算固定的标准化服务(如API封装、LoRA微调脚本开发),可以直接在一品商城下单,享受明码标价、快速交付的便捷体验。
2026年,让专业的人做专业的事。无论你是需求方还是服务方,途傲科技都为你准备好了工具箱。

