引言
痛点场景:你准备微调一个大模型,但第一个问题就把你卡住了——到底该买一台本地服务器自己跑,还是按小时租用云GPU?“买一台4090机器也就一两万,用个两三年肯定比云划算吧?”、“云上A100一小时几十块,跑一个模型岂不是要花好几千?”、“网上有人说LoRA微调几分钟就能搞定,有人说要训练好几天,到底信谁?”这些困惑几乎是每个AI从业者都会遇到的。更让人焦虑的是,选错了方案可能意味着巨大的成本浪费——一台本地机器买到手就开始贬值,而云服务看似便宜,跑着跑着账单就超出预算了。本文将通过RTX 4090和A100的实际测试数据,帮你算清楚这笔账。
核心价值:本文将基于真实场景的实测数据,从硬件门槛、训练时间、总拥有成本三个维度,对比本地部署和云微调的性价比。你不需要成为硬件专家,跟着本文的三个案例场景,就能找到适合自己的方案。
提纲预览:文章将从硬件选型的基本原则讲起,接着分析不同参数规模模型的显存和时间需求,然后通过三种典型场景(入门、进阶、专业)给出成本测算,最后总结选型决策树。

前置准备
在决定云微调还是本地跑之前,你需要先搞明白三件事。第一,你要微调的模型有多大?以LLaMA系列为例,7B到8B参数是入门级,13B到33B是中等级,70B及以上是专业级。模型参数规模直接决定了最低显存要求——7B模型全量微调需要100GB以上显存,而用QLoRA只需要12-20GB。第二,你希望微调多快完成?如果是实验性质、不着急出结果,慢一点无所谓;如果是产品上线前的紧急优化,时间成本可能比算力成本更高。第三,你的预算是资本支出还是运营支出?公司采购机器走固定资产,个人或者小团队可能更愿意按需付费。
核心硬件选型:RTX 4090 vs A100
RTX 4090和A100是目前微调领域最常见的选择,但它们的使用场景完全不同。RTX 4090配备24GB GDDR6X显存,FP16算力约23.1 TFLOPS,市场价约1.5万人民币。它是消费级显卡的天花板,性价比极高,适合个人开发者、小团队以及7B到13B模型的LoRA和QLoRA微调。它的局限也很明显:24GB显存无法全量微调7B以上的模型,而且缺乏NVLink支持,多卡训练效率受影响。
A100是数据中心级的专业GPU,有40GB和80GB两个版本,80GB版显存带宽达2TB/s,FP16算力约1000 TFLOPS。它的优势在于超大显存和专业级稳定性,一块A100 80GB可以单卡完成7B模型的全量微调,甚至支持70B模型的QLoRA微调。缺点是价格昂贵,采购价约20万人民币,云租用每小时12-18元。
核心结论很清晰:如果你想“花最少的钱跑起来”,选择RTX 4090;如果你想“挑战最大的模型”或者追求最短训练时间,选择A100。

微调时间实测:从15分钟到几十小时
时间成本是衡量方案划算与否的关键变量。根据实测数据,不同配置下的微调时间差异巨大。
对于7B规模的模型,使用QLoRA方法在单张RTX 4090上微调,数十分钟即可完成基础微调任务。更具体的数据是:用RTX 4090微调Llama 3.1 8B,训练时间约3小时,成本约219印度卢比(约合19元人民币)。如果使用A100,速度会更快——实测微调Gemma 4模型(4B参数),使用QLoRA方法,60步训练仅需8分16秒,总耗时14分38秒,成本仅0.38美元。
对于34B到70B规模的大型模型,时间会显著增加。用A100 80GB单卡对70B模型进行QLoRA微调,典型耗时约6到12小时,按每小时4.8美元计算,单次GPU成本约28到57美元。如果采用本地RTX 4090多卡方案,由于通信开销,实际训练时间可能更长。
有几个关键变量影响时间:训练步数越多时间越长,但线性增长;数据集大小直接决定每个epoch的时间;是否使用优化工具如Unsloth可以提升1.5倍速度、减少60%显存占用。
云微调 vs 本地跑:三种场景的成本测算
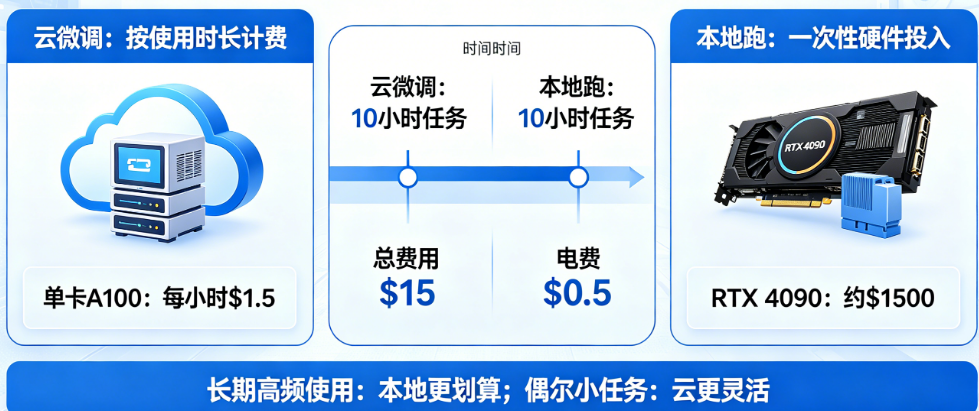
场景一:个人开发者,偶尔微调7B模型。如果你每个月只跑几次微调,每次几小时,云端租赁明显更划算。以RTX 4090为例,云租用价格约每小时1.5到2元,一次3小时的微调成本不到10元,一年下来也就几百元。如果购买一张RTX 4090,投入约1.5万元,加上电费和折旧,需要跑几千小时才能回本。对于低频使用场景,不要犹豫,直接选云端按需租用。
场景二:小团队,每周微调2-3次,持续一年。这种情况需要认真算账。一块RTX 4090的本地服务器初期投入约5万元(含主机、内存、硬盘等周边配件),加上两年电费约1万元,总成本约6万元。如果租用同等级别的云GPU,按每小时2元计算,每周跑20小时,一年约1000小时,总费用约2000元——仍然远低于本地采购。只有每周使用超过40小时(即利用率超过60%),本地部署才开始显现经济性优势。对于大多数小团队,云的灵活性更有价值。
场景三:企业级,需要全量微调70B模型。这种情况下,本地部署可能需要采购A100或H100集群,单块A100 80GB价格约20万元,四卡集群轻松破百万。而云端租用A100 80GB每小时约12到18元,一次完整微调按12小时计算约200元。即便是每周跑一次,年花费也远低于采购成本。只有当团队几乎不间断地在训练(每周超过60小时),自建集群才在三年TCO上有优势。
进阶优化:如何进一步降低成本
无论选择云还是本地,都有成熟的降本方法。QLoRA是最大的省钱利器——相比全量微调,它让7B模型从100GB显存需求降至12-20GB,意味着原本需要A100才能跑的任务,现在RTX 4090就可以胜任。利用Spot实例或社区云可以进一步降低云成本,比如SaladCloud上的RTX 4090仅需每小时0.35美元(约2.5元人民币)。善用预训练模型和PEFT方法,LoRA可以在保持全量微调90%-95%质量的同时,将训练时间缩短到十分之一。最后,按需选型、渐进投入——不要一开始就买最高配置,先用云端验证想法,确定需求后再决定是否自建。
常见问答
问:QLoRA微调能达到全量微调的效果吗?实测中,QLoRA在大多数任务上能恢复全量微调80%-90%的质量,LoRA则能恢复90%-95%。对于绝大多数业务场景,这个差距可以接受。
问:A100一定比4090快吗?对于同等显存需求的任务,是的。A100的显存带宽和算力都远超4090,尤其是大模型推理和训练时差距明显。但如果你的模型在4090上就能跑满,升级到A100并不会带来线性提升。
问:我应该先买显卡还是先租云?对于不确定长期需求的团队,强烈建议从云端租赁开始。云服务按秒计费,实验成本可控,验证可行性后再决定是否自建。
总结
云微调和本地跑没有绝对的“更好”,只有“更适合”。对于个人开发者和低频用户,云端按需租用是最省心的选择——你不需要一次性投入几万元,也不需要操心硬件维护。对于高频使用的小团队,如果每周训练超过40小时,可以考虑自建RTX 4090机器,两年内能回本。对于需要大规模训练的企业,短期看云更灵活,长期看自建集群在TCO上有优势。最后送大家一句话:用QLoRA降低门槛,用云端验证需求,用数据做决策,不要拍脑袋。
途傲科技任务大厅每天都有大量AI模型微调和部署的需求发布,从LLaMA微调到Stable Diffusion训练,场景丰富。如果你正在为GPU资源选型而纠结,或者需要专业的技术团队帮你完成模型微调,不妨在任务大厅发布你的具体需求,详细说明模型规模、数据量、时间要求和预算范围,平台会快速为你匹配合适的算法工程师。你也可以在人才大厅按技能标签搜索“大模型微调”“LoRA”“PyTorch”等关键词,查看服务商的过往案例和客户评价,选择有实战经验的人选合作。想了解成功项目是如何控制成本的,可以进入服务大厅浏览各类商铺案例,看看别人是如何平衡云端租赁和本地部署的。别忘了收藏威客攻略栏目学习模型优化和成本控制技巧,开通V客优享会员更能享受优先推荐和专属客服,真正改变你的工作方式。途傲科技汇聚百万服务商提供从模型训练、微调到推理部署的全流程AI技术服务,你还可以通过途傲科技网热门标签频道,如“大模型微调”“GPU租用”“AI训练”等热门搜索词,快速定位优质服务商,享受高效、透明、专业的一站式网站体验,让你的AI项目从选型开始就走对方向。

